Know your Parquet files, and you know your scaling limits
The Apache Parquet file format is popular for storing and interchanging tabular data. It is self-contained, well compressed, supports parallel reading, reading selected columns only, and filtering on values (to some extent). These properties make Parquet the ideal input file format for distributed data processing platforms like Apache Spark.
The greatest feature of Apache Spark is that once it works with a small chunk of data, it can work with any (really any!) size of data, as long as it can split the data into those small chunks. Then, each chunk can be processed in parallel. By adding processing power (Spark executors) you can scale up your input data without sacrificing on wall clock processing time. In other words, you are able to scale with your growing data. But are there limits to scaling?
Splitting input data into small chunks is paramount when entering Big Data land. The Parquet file format is known to be splittable[1],[2] However, it is crucial to understand that Parquet files are not arbitrarily splittable. While the file format supports splitting, individual files might not be splittable at all. With such files, you will be asked to leave Big Data land again.
We will see a new way to easily inspect Parquet files with Spark to understand their internal structure. Then, we will learn how Spark attempts to split those files and identify the upper limit of read scalability.
The Parquet file structure
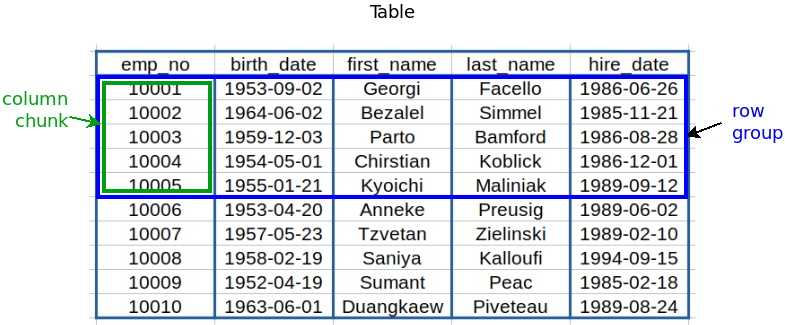
The Parquet file format stores tabular data, i.e. values organized in columns and rows.
Such a table is split by Parquet into blocks of consecutive rows (called row groups), while each block stores the values column by column (called column chunks). Each column chunk is further split into column pages.
Here is an example table[3]:
Column chunks are the main content of a Parquet file. They are written to the file in the following sequence:
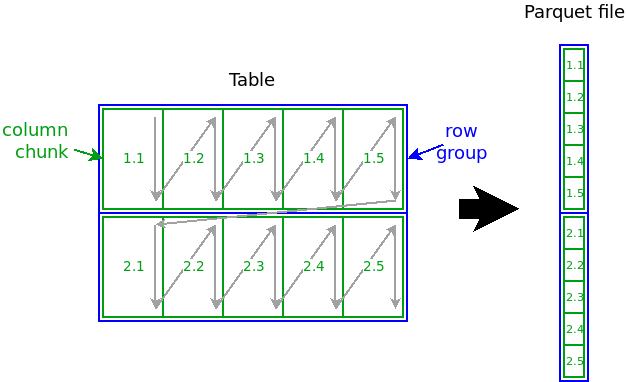
The location (starting position within the file) of row groups and column chunks can be determined from the file footer, a section at the end of the file that contains metadata about the file structure. By reading the footer, the reader can jump directly to the position in the file where row groups and column chunks start. This allows for parallel reading without the need to read unrelated rows or columns.
The Parquet specification states that a column page is the smallest part of a Parquet file that is not splittable. In order to read a value at the end of a column page, the entire page up to that value has to be read. However, a Parquet file is best split on row group boundaries, as this involves the fewest file seek operations with the highest “relevant bytes” to “read bytes” ratio.
Inspecting Parquet files with Spark
There exist tools like Parquet CLI (Java, Python) or its predecessor Parquet Tools (Java, Python), that allow to inspect the inner structure of Parquet files.
The Spark Extension package (starting with release v2.6.0) reads those Parquet metadata into a Spark Dataframe in a scalable way:
import uk.co.gresearch.spark.parquet._
spark.read.parquetMetadata("/path/to/parquet").show()
import gresearch.spark.parquet
spark.read.parquet_metadata("/path/to/parquet").show()
+-------------+------+-------------+---------------+----+------------------+------------------+ | filename|blocks|compr…edBytes|uncompr…edBytes|rows| createdBy| schema| +-------------+------+-------------+---------------+----+------------------+------------------+ |file1.parquet| 1| 1268| 1652| 100|parquet-mr versio…|message spark_sch…| |file2.parquet| 2| 2539| 3302| 200|parquet-mr versio…|message spark_sch…| +-------------+------+-------------+---------------+----+------------------+------------------+
Parquet metadata can be read on file level, row group level, column chunk level and Spark Parquet partition level.
Any location that can be read by Spark (spark.read.parquet(…)) can be inspected. This means the path can point to a single Parquet file, a directory with Parquet files, or multiple paths separated by a comma (,). Paths can contain wildcards like *. Multiple files will be inspected in parallel and distributed by Spark. No actual rows or values will be read from the Parquet files, only metadata, which is very fast. This allows you to inspect Parquet files that have different schemata with one spark.read operation.
Using the Spark Extension
The Spark Extension package has to be added to your Spark job as a dependency first:
libraryDependencies += "uk.co.gresearch.spark" %% "spark-extension" % "2.6.0-3.3"
<dependency> <groupId>uk.co.gresearch.spark</groupId> <artifactId>spark-extension_2.12</artifactId> <version>2.6.0-3.3</version> </dependency>
from pyspark.sql import SparkSession
spark = SparkSession
.builder
.config("spark.jars.packages", "uk.co.gresearch.spark:spark-extension_2.12:2.6.0-3.3")
.getOrCreate()
spark-submit --packages uk.co.gresearch.spark:spark-extension_2.12:2.6.0-3.3 [jar | script.py]
Carefully pick the Scala (here 2.12) and Spark (here 3.3) compatibility versions.
See the documentation for various descriptions of how to do this.
Using the Parquet metadata to understand how Spark partitions Parquet files
Understanding the structure of a Parquet file is crucial to predicting how Spark is going to partition the file.
Spark splits Parquet files into equal-sized partitions. The partition size is not derived from the actual Parquet file, but determined by the spark.sql.files.maxPartitionBytes option. Row groups are never split, they completely belong to exactly one partition, which is particularly tricky at partition boundaries. Note that the partition which contains the middle byte of a row group is responsible for reading that row group:
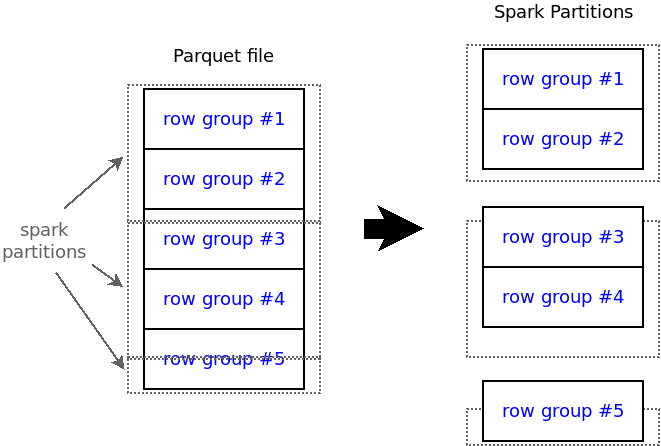
Splitting a Parquet file into way more partitions than there are row groups results in many empty partitions:
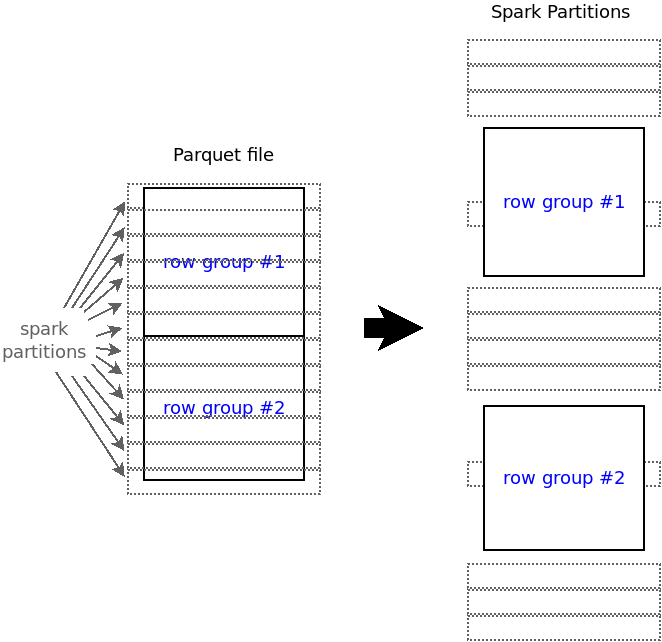
Once you know the number of row groups of your Parquet file, you know into how many non-empty partitions the file may be split by Spark.
Reading the Spark Parquet partitioning metadata
These insights can be obtained programmatically from Parquet files by reading their Spark Parquet partitioning metadata:
spark.read.parquetPartitions("/path/to/parquet").show()
spark.read.parquet_partitions("/path/to/parquet").show()
+---------+-----+----+------+------+-------------+---------------+----+-------------+----------+ |partition|start| end|length|blocks|compr…edBytes|uncompr…edBytes|rows| filename|fileLength| +---------+-----+----+------+------+-------------+---------------+----+-------------+----------+ | 1| 0|1024| 1024| 1| 1268| 1652| 100|file1.parquet| 1930| | 2| 1024|1930| 906| 0| 0| 0| 0|file1.parquet| 1930| | 3| 0|1024| 1024| 1| 1269| 1651| 100|file2.parquet| 3493| | 4| 1024|2048| 1024| 1| 1270| 1651| 100|file2.parquet| 3493| | 5| 2048|3072| 1024| 0| 0| 0| 0|file2.parquet| 3493| | 6| 3072|3493| 421| 0| 0| 0| 0|file2.parquet| 3493| +---------+-----+----+------+------+-------------+---------------+----+-------------+----------+
We can see that in our example directory /path/to/parquetcontains two Parquet files, file1.parquet and file2.parquet, with 1 and 2 blocks (row groups), as well as 100 and 200 rows, respectively. The Parquet files are split into six equal-sized partitions of 1024 bytes (length), except for the last partition of each file. The partition boundaries (startand end) are determined by the file size (fileLength) and the spark.sql.files.maxPartitionBytesvalue of 1024 (specifically set for this example).
Even though Spark splits the Parquet file into many partitions (file file1.parquet is split into two and file file2.parquet into four partitions), some partitions are empty (partitions 2, 5 and 6).
This can also be observed with the help of the Spark UI:
Note that the Index column in the Spark UI does not correspond to the partition column in the table above.
It is important to understand that the number of partitions is no indication of how well your Parquet file can be split. Splitting the above example into more partitions would increase parallelism and thus not reduce the overall wall-clock time.
Your Parquet file only scales with the number of non-empty partitions, which is limited by the number of row groups. This determines the upper boundary of parallelism when reading those files. Therefore, those example files do not scale beyond three partitions or executors.
Improving Parquet reading scalability
It is recommended to have one row group to fit into one filesystem block (e.g. HDFS[4]). Hence, your filesystem defines the lower limit for the row group size. The default HDFS block size is 128 MB[5], which is also the default for Spark’s max partition size[6] set via spark.sql.files.maxPartitionBytes.
If row groups in your Parquet file are much larger than your HDFS block size, you have identified the potential to improve scalability of reading those files with Spark. Creating those Parquet files with a block size matching your HDFS block size will allow for better partitioning.
Conclusion
We have seen that Parquet files are not arbitrarily splittable, and understanding how individual files are structured is key to knowing their upper limit on parallelism when reading them. The Spark Extension package provides an easy way to read the Parquet metadata into a Spark DataFrame to programmatically mass-inspect Parquet files and to analyze how they are partitioned.
[1] https://parquet.apache.org/docs/concepts/
[2] https://boristyukin.com/is-snappy-compressed-parquet-file-splittable/
[3] Example table taken from a MySQL sample database under Creative Commons 3.0: https://github.com/datacharmer/test_db#disclaimer
[4] Apache Parquet configuration – Row Group Size: https://parquet.apache.org/docs/file-format/configurations/#row-group-size
[5] Apache Hadoop HDFS Design: https://hadoop.apache.org/docs/r3.1.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Blocks
[6] Apache Spark Performance Tuning: https://spark.apache.org/docs/3.4.0/sql-performance-tuning.html#other-configuration-options


